When an application calls the new operator to create an object, there might not be enough address space left in the region to allocate the object. If insufficient space exists, then the CLR performs a GC.
For managing the lifetime of objects, some systems use a reference counting algorithm. In fact, Microsoft’s own Component Object Model (COM) uses reference counting. With a reference counting system, each object on the heap maintains an internal field indicating how many “parts” of the program are currently using that object. As each “part” gets to a place in the code where it no longer requires access to an object, it decrements that object’s count field. When the count field reaches 0, the object deletes itself from memory. The big problem with many reference counting systems is that they do not handle circular references well. For example, in a GUI application, a window will hold a reference to a child UI element. And the child UI element will hold a reference to its parent window. These references prevent the two objects’ counters from reaching 0, so both objects will never be deleted even if the application itself no longer has a need for the window.
Due to this problem with reference counting garbage collector algorithms, the CLR uses a referencing tracking algorithm instead. The reference tracking algorithm cares only about reference type variables, because only these variables can refer to an object on the heap; value type variables contain the value type instance directly. Reference type variables can be used in many contexts: static and instance fields within a class or a method’s arguments or local variables. We refer to all reference type variables as roots. Many objects on a heap are linked one to the other forming a chain, depending on which object is referenced by whom. There might be multiple such chains in the heap. The reference to the first object, i.e. the memory location to any such chain is called a Root. Every application has a set of such roots. E.g. the global and static object pointers, any local variable/parameter object pointers and any CPU registers containing pointers to objects.
All these roots are stored in the Application stack and identify storage locations, which refer to objects on the managed heap or to objects that are set to null. This list of active roots is maintained by the just-in-time (JIT) compiler and common language runtime, and is made accessible to the garbage collector’s algorithm.
When the CLR starts a GC, the CLR first suspends all threads in the process. This prevents threads from accessing objects and changing their state while the CLR examines them. Then, the CLR performs what is called the marking phase of the GC. First, it walks through all the objects in the heap setting a bit (contained in the sync block index field) to 0. This indicates that all objects should be deleted. Then, the CLR looks at all active roots to see which objects they refer to. This is what makes the CLR’s GC a reference tracking GC. If a root contains null, the CLR ignores the root and moves on to examine the next root.
Any root referring to an object on the heap causes the CLR to mark that object. Marking an object means that the CLR sets the bit in the object’s sync block index to 1. When an object is marked, the CLR examines the roots inside that object and marks the objects they refer to. If the CLR is about to mark an already-marked object, then it does not examine the object’s fields again. This prevents an infinite loop from occurring in the case where you have a circular reference.
Below Figure shows a heap containing several objects. In this example, the application roots refer directly to objects A, C, D, and F. All of these objects are marked. When marking object D, the garbage collector notices that this object contains a field that refers to object H, causing object H to be marked as well. The marking phase continues until all the application roots have been examined.

Once complete, the heap contains some marked and some unmarked objects. The marked objects must survive the collection because there is at least one root that refers to the object; we say that the object is reachable because application code can reach (or access) the object by way of the variable that still refers to it. Unmarked objects are unreachable because there is no root existing in the application that would allow for the object to ever be accessed again.
Now that the CLR knows which objects must survive and which objects can be deleted, it begins the GC’s compacting phase. During the compacting phase, the CLR shifts the memory consumed by the marked objects down in the heap, compacting all the surviving objects together so that they are contiguous in memory. This serves many benefits. First, all the surviving objects will be next to each other in memory; this restores locality of reference reducing your application’s working set size, thereby improving the performance of accessing these objects in the future. Second, the free space is all contiguous as well, so this region of address space can be freed allowing other things to use it.
Finally, compaction means that there are no address space fragmentation issues with the managed heap as is known to happen with native heaps. When compacting memory, the CLR is moving objects around in memory. This is a problem because any root that referred to a surviving object now refers to where that object was in memory; not where the object has been relocated to. When the application’s threads eventually get resumed, they would access the old memory locations and corrupt memory. Clearly, this can’t be allowed and so, as part of the compacting phase, the CLR subtracts from each root the number of bytes that the object it referred to was shifted down in memory. This ensures that every root refers to the same object it did before; it’s just that the object is at a different location in memory.
After the heap memory is compacted, the managed heap’s NextObjPtr pointer is set to point to a location just after the last surviving object. This is where the next allocated object will be placed in memory. below figure shows the managed heap after the compaction phase. Once the compaction phase is complete, the CLR resumes all the application’s threads and they continue to access the objects as if the GC never happened at all.

If the CLR is unable to reclaim any memory after a GC and if there is no address space left in the processes to allocate a new GC segment, then there is just no more memory available for this process. In this case, the new operator that attempted to allocate more memory ends up throwing an OutOfMemoryException. Your application can catch this and recover from it but most applications do not attempt to do so; instead, the exception becomes an unhandled exception, Windows terminates the process, and then Windows reclaims all the memory that the process was using.
As a programmer, notice how the two bugs described at the beginning of this chapter no longer exist. First, it’s not possible to leak objects because any object not accessible from your application’s roots will be collected at some point. Second, it’s not possible to corrupt memory by accessing an object that was freed because references can only refer to living objects, since this is what keeps the objects alive anyway.
Important A static field keeps whatever object it refers to forever or until the AppDomain that the types are loaded into is unloaded. A common way to leak memory is to have a static field refer to a collection object and then to keep adding items to the collection object. The static field keeps the collection object alive and the collection object keeps all its items alive. For this reason, it is best to avoid static fields whenever possible.
Garbage Collection generations
The CLR’s GC is a generational garbage collector (also known as an ephemeral garbage collector,
although I don’t use the latter term in this book). A generational GC makes the following assumptions
about your code:
- The newer an object is, the shorter its lifetime will be.
- The older an object is, the longer its lifetime will be.
- Collecting a portion of the heap is faster than collecting the whole heap.
When initialized, the managed heap contains no objects. Objects added to the heap are said to be in generation 0. Stated simply, objects in generation 0 are newly constructed objects that the garbage collector has never examined. Figure below shows a newly started application with five objects allocated (A through E). After a while, objects C and E become unreachable.

When the CLR initializes, it selects a budget size (in kilobytes) for generation 0. So if allocating a new object causes generation 0 to surpass its budget, a garbage collection must start. Let’s say that objects A through E fill all of generation 0. When object F is allocated, a garbage collection must start. The garbage collector will determine that objects C and E are garbage and will compact object D, causing it to be adjacent to object B. The objects that survive the garbage collection (objects A, B, and D) are said to be in generation 1. Objects in generation 1 have been examined by the garbage collector once. The heap now looks like Figure below.
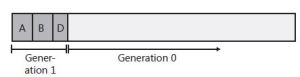
After a garbage collection, generation 0 contains no objects. As always, new objects will be allocated in generation 0. Figure BELOW shows the application running and allocating objects F through K. In addition, while the application was running, objects B, H, and J became unreachable and should have their memory reclaimed at some point.

Now let’s say that attempting to allocate object L would put generation 0 over its budget. Because generation 0 has reached its budget, a garbage collection must start. When starting a garbage collection, the garbage collector must decide which generations to examine. Earlier, WE said that when the CLR initializes, it selects a budget for generation 0. Well, it also selects a budget for generation 1. When starting a garbage collection, the garbage collector also sees how much memory is occupied by generation 1. In this case, generation 1 occupies much less than its budget, so the garbage collector examines only the objects in generation 0. Look again at the assumptions that the generational garbage collector makes. The first assumption is that newly created objects have a short lifetime. So generation 0 is likely to have a lot of garbage in it, and collecting generation 0 will therefore reclaim a lot of memory. The garbage collector will just ignore the objects in generation 1, which will speed up the garbage collection process.
Obviously, ignoring the objects in generation 1 improves the performance of the garbage collector. However, the garbage collector improves performance more because it doesn’t traverse every object in the managed heap. If a root or an object refers to an object in an old generation, the garbage collector can ignore any of the older objects’ inner references, decreasing the amount of time required to build the graph of reachable objects. Of course, it’s possible that an old object’s field refers to a new object. To ensure that the updated fields of these old objects are examined, the garbage collector uses a mechanism internal to the JIT compiler that sets a bit when an object’s reference field changes. This support lets the garbage collector know which old objects (if any) have been written to since the last collection. Only old objects that have had fields change need to be examined to see whether they refer to any new object in generation 0.
A generational garbage collector also assumes that objects that have lived a long time will continue to live. So it’s likely that the objects in generation 1 will continue to be reachable from the application. Therefore, if the garbage collector were to examine the objects in generation 1, it probably wouldn’t find a lot of garbage. As a result, it wouldn’t be able to reclaim much memory. So it is likely that collecting generation 1 is a waste of time. If any garbage happens to be in generation 1, it just stays there. The heap now looks like Figure below.

As you can see, all of the generation 0 objects that survived the collection are now part of generation 1. Because the garbage collector didn’t examine generation 1, object B didn’t have its memory reclaimed even though it was unreachable at the time of the last garbage collection. Again, after a collection, generation 0 contains no objects and is where new objects will be placed. In fact, let’s say that the application continues running and allocates objects L through O. And while running, the application stops using objects G, L, and M, making them all unreachable. The heap now looks like figure below
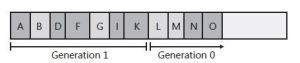
Let’s say that allocating object P causes generation 0 to exceed its budget, causing a garbage collection to occur. Because the memory occupied by all of the objects in generation 1 is less than its budget, the garbage collector again decides to collect only generation 0, ignoring the unreachable objects in generation 1 (objects B and G). After the collection, the heap looks like Figure below.
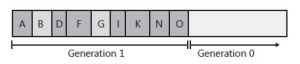
In Figure above, you see that generation 1 keeps growing slowly. In fact, let’s say that generation 1 has now grown to the point in which all of the objects in it occupy its full budget. At this point, the application continues running (because a garbage collection just finished) and starts allocating objects P through S, which fill generation 0 up to its budget. The heap now looks like Figure below.

When the application attempts to allocate object T, generation 0 is full, and a garbage collection must start. This time, however, the garbage collector sees that the objects in generation 1 are occupying so much memory that generation 1’s budget has been reached. Over the several generation 0 collections, it’s likely that a number of objects in generation 1 have become unreachable (as in our example). So this time, the garbage collector decides to examine all of the objects in generation 1 and generation 0. After both generations have been garbage collected, the heap now looks like Figure below.

As before, any objects that were in generation 0 that survived the garbage collection are now in generation 1; any objects that were in generation 1 that survived the collection are now in generation 2. As always, generation 0 is empty immediately after a garbage collection and is where new objects will be allocated. Objects in generation 2 are objects that the garbage collector has examined two or more times. There might have been several collections, but the objects in generation 1 are examined only when generation 1 reaches its budget, which usually requires several garbage collections of generation 0.
The managed heap supports only three generations: generation 0, generation 1, and generation 2; there is no generation 3.23 When the CLR initializes, it selects budgets for all three generations. However, the CLR’s garbage collector is a self-tuning collector. This means that the garbage collector learns about your application’s behavior whenever it performs a garbage collection. For example, if your application constructs a lot of objects and uses them for a very short period of time, it’s possible that garbage collecting generation 0 will reclaim a lot of memory. In fact, it’s possible that the memory for all objects in generation 0 can be reclaimed. If the garbage collector sees that there are very few surviving objects after collecting generation 0, it might decide to reduce the budget of generation 0. This reduction in the allotted space will mean that garbage collections occur more frequently but will require less work for the garbage collector, so your process’s working set will be small. In fact, if all objects in generation 0 are garbage, a garbage collection doesn’t have to compact any memory; it can simply set NextObjPtr back to the beginning of generation 0, and then the garbage collection is performed. Wow, this is a fast way to reclaim memory!
Note The garbage collector works extremely well for applications with threads that sit idle at the top of their stack most of the time. Then, when the thread has something to do, it wakes up, creates a bunch of short-lived objects, returns, and then goes back to sleep. Many applications follow this architecture. For example, GUI applications tend to have the GUI thread sitting in a message loop most of its life. Occasionally, the user generates some input (like a touch, mouse, or keyboard event), the thread wakes up, processes the input and returns back to the message pump. Most objects created to process the input are probably garbage now. Similarly, server applications tend to have thread pool threads sitting in the pool waiting for client
requests to come in. When a client request comes in, new objects are created to perform work on behalf of the client request. When the result is sent back to the client, the thread returns to the thread pool and all the objects it created are garbage now.
On the other hand, if the garbage collector collects generation 0 and sees that there are a lot of
surviving objects, not a lot of memory was reclaimed in the garbage collection. In this case, the
garbage collector will grow generation 0’s budget. Now, fewer collections will occur, but when they do, a lot more memory should be reclaimed. By the way, if insufficient memory has been reclaimed after a collection, the garbage collector will perform a full collection before throwing an OutOfMemoryException.
Throughout this discussion, we’ve been talking about how the garbage collector dynamically modifies generation 0’s budget after every collection. But the garbage collector also modifies the budgets of generation 1 and generation 2 by using similar heuristics. When these generations are garbage collected, the garbage collector again sees how much memory is reclaimed and how many objects survived. Based on the garbage collector’s findings, it might grow or shrink the thresholds of these generations as well to improve the overall performance of the application. The end result is that the garbage collector fine-tunes itself automatically based on the memory load required by your application—this is very cool!
Large Objects
There is one more performance improvement you might want to be aware of. The CLR considers each single object to be either a small object or a large object. So far, in this chapter, I’ve been focusing on small objects. Today, a large object is 85,000 bytes or more in size.24 The CLR treats large objects slightly differently that how it treats small objects:
- Large objects are not allocated within the same address space as small objects; they are allocated elsewhere within the process’ address space.
- Today, the GC doesn’t compact large objects because of the time it would require to move them in memory. For this reason, address space fragmentation can occur between large objects within the process leading to an OutOfMemoryException being thrown. In a future version of the CLR, large objects may participate in compaction.
- Large objects are immediately considered to be part of generation 2; they are never in generation 0 or 1. So, you should create large objects only for resources that you need to keep alive for a long time. Allocating short-lived large objects will cause generation 2 to be collected more frequently, hurting performance. Usually large objects are large strings (like XML or JSON) or byte arrays which you use for I/O operations, such as reading bytes from a file or network
In the future, the CLR could change the number of bytes required to consider an object to be a large object. Do not count 85,000 being a constant into a buffer so you can process it. For the most part, large objects are transparent to you; you can simply ignore that they exist and that they get special treatment until you run into some unexplained situation in your program.
P.S. Thanks to Jefrey Ritcher’s Book CLR Via C# for the content 🙂
















